Все действия будут проводиться на примере Электронного архива Уральского федерального университета и DSpace версии 1.8.х.
Что такое sitemap объяснять не буду, ибо данная заметка рассчитана на людей понимающих суть инструмента и понимающих его важность. DSpace умеет генерировать sitemap’ы стандартными средствами и этого в целом достаточно, но есть возможность сервису помочь.
Стандартный метод работает так:
- В dspace.cfg параметр sitemap.dir делается равным директории веб интерфейса (xmlui или jspui)
- По планировщику регулярно (например, раз в сутки) выполняется команда [dspace]/bin/dspace generate-sitemaps
- В robots.txt добавляется строка Sitemap: http://YOURSERVICENAME/sitemap_index.xml.gz
- Путь до сайтмапа (именно до sitemap_index.xml.gz) руками прописывается в google, bing и yandex инструментах для вебмастера.
Можно параметр sitemap.dir не трогать, а по планировщику выполнять не только генерацию сайтмапа, но и его копирование, например так:
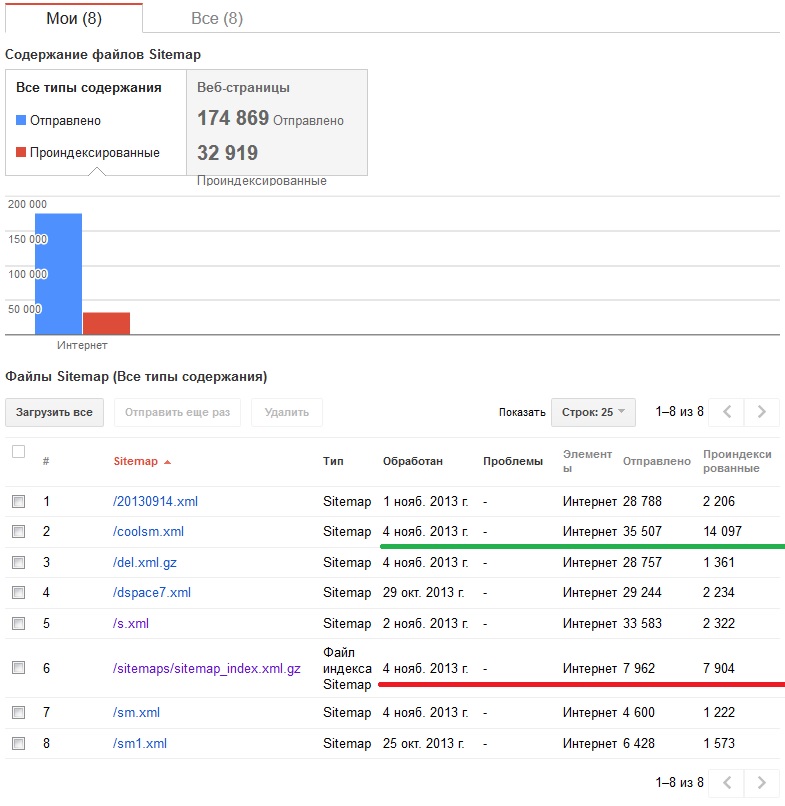
В результате создастся по всем статьям правильный сайтмап, который будет посечен на файлы по 5 тысяч (кажется) ссылок, зажат в gzip и снабжен индексом. Количество ссылок будет равно количеству хэндлов. На момент написания заметки для Электронного архива УрФУ количество ссылок было равно 7962-ум штукам. заглавий было 7869, так что не сложно подсчитать сколько в архиве разделов и коллекций. Иных сущностей, обремененных хэндлами в архиве разумеется нет. Почти восемь тысяч, много это или мало? Учитывая, что проиндексированных страниц по данным google более восьмидесяти тысяч, я делаю вывод что это скорее МАЛО чем много. Вот собственно и начинается самое интересное….
Генерация карты архива внешними средствами
Для начала я попытался изучить инструменты, генерирующие sitemap’ы онлайн. После некоторых поисков остановился на этом. Он прикольный, он может сгенерировать почти ни разу не упав при этом карту с очень большим количеством ссылок — 200-300 тысяч ссылок для рассматриваемого архива. Конечно, в такой карте много мусора, конечно, google берет из неё от силы 5-10% ссылок, но основным посылом искать дальше стал тот факт чтос айтмап посредством данного сервиса может генерироваться сколь угодно долго. Я просто останавливал процесс на двухстах тысячах, ибо шли вторые сутки генерации. Для некоторого повышения количества страниц в индексе данный инструмент пригоден, но для регулярной генерации нет. Работает он лучше всего под 32 bit java 6, посредством апплета панели управления очень желательно выделить яве 1320 мегабайт памяти. Больше не съест, а меньше… в общем, упадет. Да, google относительно безболезненно переваривает файлы с десятками тысяч ссылок вне архивов, для андекса и бинга лучше сайтмап побить на кусочки и зажать. Соответствующие галочки в диалоге сохранения есть.
Итогом использования внешних онлайн инструментов стал двукратный рост проиндексированных страниц и более чем десятикратный рост отправленных страниц. Приятно конечно, ибо 14 тысяч больше чем 7, но невозможность быстрой актуализации и низкое качество (ведь 90 тысяч отправленных страниц принесли лишь 14 тысяч проиндексированных) заставили двигаться дальше.
А давайте руками
Механизм генерации карты сайта руками особо ничего не сулил, но в случае чего, его можно было реализовать в виде скрипта на обработке регекспов. Идея была следующая:
- Идем в архив и смотрим сколько у нас заглавий, сколько у нас авторов и сколько у нас тем (всё в штуках).
- Сохраняем понятные в общем-то страницы, специально привожу адреса полностью:
- elar.urfu.ru/browse?type=title&rpp=7869
- http://elar.urfu.ru/browse?type=author&rpp=7404
- elar.urfu.ru/browse?type=subject&rpp=20233
- До кучи можно сохранить еще и http://elar.urfu.ru/community-list
- Думаю, смысл уже понятен, но уточню — эти четыре страницы содержат ссылки на каждую запись, каждого автора, каждый раздел и коллекцию и каждую тематику архива.
- Из всего этого нужно сделать sitemap…
Как я делал sitemap руками первый раз:
- Собрал весь HTML код в один файл.
- Удалил ссылки на авторов из таблицы «По заглавию».
- Упростил ссылки т.е. от ссылки вида
/browse?type=author&order=ASC&rpp=20&value=Aksenova%2C+T.+V.
оставил лишь
http://elar.urfu.ru/browse?type=author&value=Aksenova%2C+T.+V.
со ссылками на тематики и заглавия аналогично, параметры сортировки и вывода строк на страницу были удалены, хостнейм добавлен. - Удалил все теги, касающиеся таблиц.
- Оставил в коде только значения параметров href (т.е. в файле остались только ссылки и всё!)
- Добавил в начало каждой строки
<url><loc>
и в конец
</loc></url> - Добавил валидную шапку сайтмапа.
В итоге получился файл приличного веса содержащий чуть более тридцати пяти тысяч ссылок. Google Webmaster Tools за сутки проиндексировал 70% этого количества ссылок и рост продолжается!!!
Заключение
Кажется, что создать такой сайтмап сложно, но я попробовал два пути — shell+grep и как ни странно csv+excel. Оба работают по принципу разделения и замены и дали аналогичный результат. Оба потребовали 5-7 минут времени. Учитывая «качество» и мизерные временные затраты (вспоминаем о суточных генерациях посредством веб сервисов), а так же возможность полностью автоматизировать этот процесс, считаю опыт удачным и полезным.
На картинке ниже красным помечен стандартный сайтмап, зеленым — созданный руками. Остальные — созданные различными веб сервисами. Картинка сделана практически сразу после добавления сайтмапа, но соотношение количества отправленных и проиндексированных страниц уже заметно.
[UPD]
Этот скриншот наверное, даже более показателен:
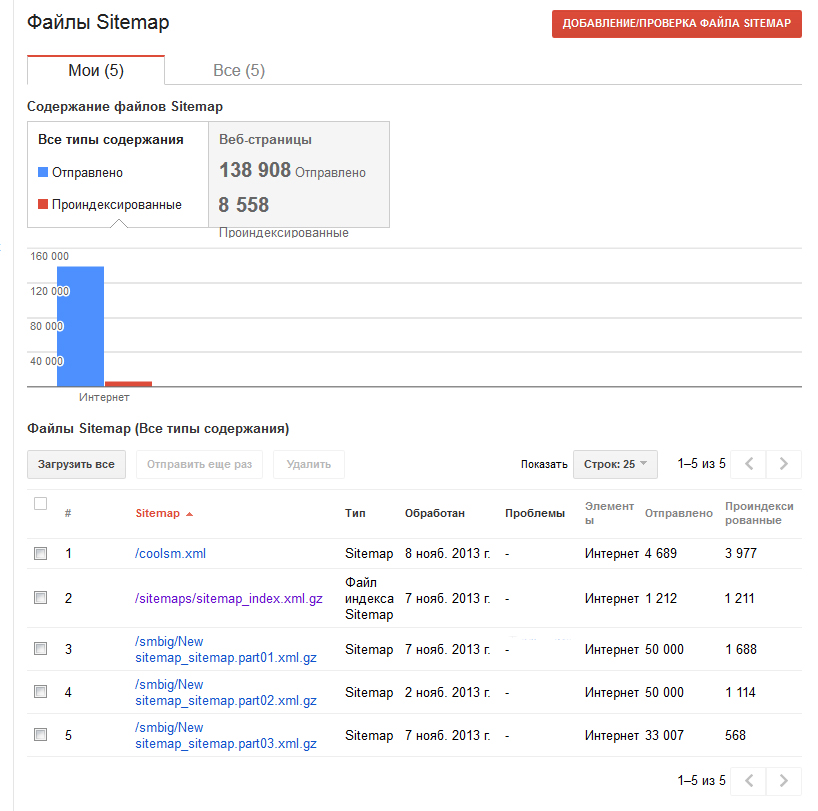
Первая строка — сайтмап, сделанный вручную.
Вторая строка — автоматически созданный сайтмап.
Третья, четвертая и пятая строки — сайтмап, созданный посредством веб сервиса.
Комментарии, думаю, не нужны.
Пользуюсь Вашими статьями, как руководством к действию, огромное спасибо!
Сделал, как описано в статье. Не получилось… Search Console при тестировании файла сайтмапа выдавал сообщение — «не могу прочитать файл» . Оказалось все очень просто — если в xml-файле нам нужно поместить ссылку вида «http://elar.urfu.ru/browse?type=author&value=Aksenova%2C+T.+V.» то необходимо вспомнить (а таким как я — изучить матчасть:-)) — ЗНАК АМПЕРСАНТА ЯВЛЯЕТСЯ СЛУЖЕБНЫМ, поэтому его необходимо заменить на &
Плиз, подкорректируйте свою статья для таких, как я 🙂
Заранее благодарю
С уважением,
Van
http://elar.urfu.ru/coolsm.xml работает… а вот с кодированием символов и с кавычками не работало.
Во всяком случае — мне помогла именно замена символа амперсанта на последовательность: АМПЕРСАНТ потом без пробела amp и затем двоеточие
Пишу словами, ибо при попытке напрямую написать — отображается только амперсант 🙁
Благодарю за внимание
Ну, не двоеточие, а точка с запятой, видимо.
Сорри, невнимательность… (
Таки да, точка с запятой